Media Coverage

Teaser
Abstract
This work introduces Robots Imitating Generated Videos (RIGVid), a system that enables robots to perform complex manipulation tasks—such as pouring, wiping, and mixing—purely by imitating AI-generated videos, without requiring any physical demonstrations or robot-specific training. Given a language command and an initial scene image, a video diffusion model generates potential demonstration videos, and a vision-language model (VLM) automatically filters out results that do not follow the command. A 6D pose tracker then extracts object trajectories from the video, and the trajectories are retargeted to the robot in an embodiment-agnostic fashion. Through extensive real-world evaluations, we show that filtered generated videos are as effective as real demonstrations, and that performance improves with generation quality. We also show that relying on generated videos outperforms more compact alternatives such as keypoint prediction using VLMs, and that strong 6D pose tracking outperforms other ways to extract trajectories, such as dense feature point tracking. These findings suggest that videos produced by a state-of-the-art off-the-shelf model can offer an effective source of supervision for robotic manipulation.
Explanation Video
Robot Imitating Generated Videos (RIGVid)

RIGVid eliminates the need for physical demonstrations by leveraging video generation and 6D pose tracking. Given RGBD observations and a language command, it generates a video of the task, predicts depth, and tracks the manipulated object's 6D pose over time. It is then retargeted to robot for execution. The approach is embodiment-agnostic, robust to disturbances, and achieves state-of-the-art zero-shot performance.
Interactive Visualizations
Object Trajectory
Demonstrations
Embodiment-Agnostic & Bimanual Manipulation
RIGVid execution on XArm7 and Aloha, showcasing embodiment‑agnostic capabilities.
RIGVid allows for bimanual manipulation. In this example, it places two shoes simultaneously.
Robustness
Insights
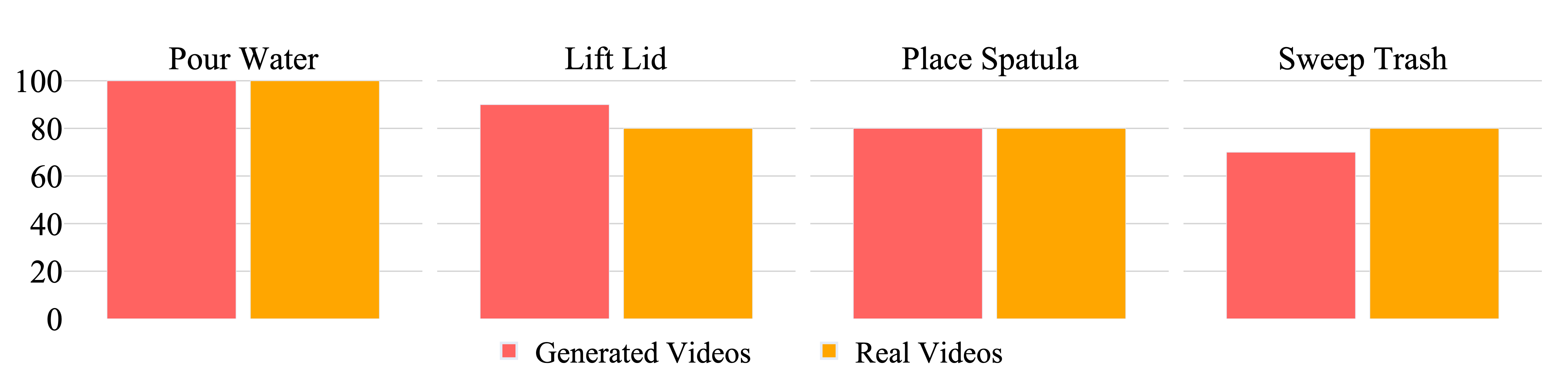
Insight #1: Imitating generated videos can be as good as imitating real videos
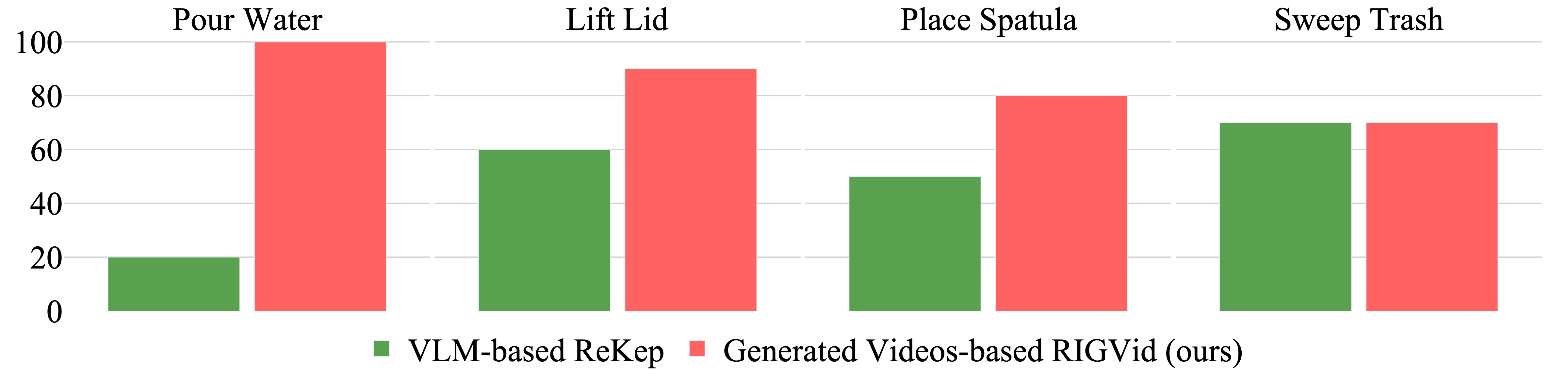
Insight #2: RIGVid outperforms VLM-based zero-shot method
Insight #3: Better video generator leads to higher success rate
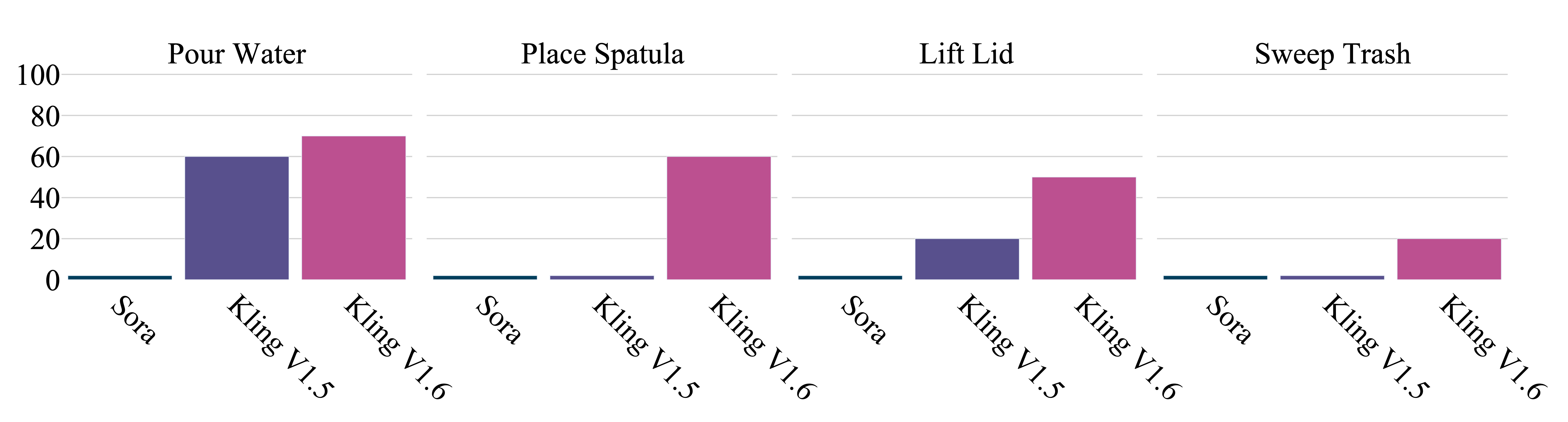
Results
RIGVid outperforms other video-generation for robotics works